
 Country
Country India
India 대한민국
대한민국 Nederlands
Nederlands
Have you ever tried to build an API and make everyone that uses it happy? It’s often a hard, if not impossible task. You never know how your end users will want to use it, but Facebook may have found a solution. In 2015, they released GraphQL to the public. It is not a piece of software, but rather a query language for API’s. They left implementation up to the development community and now various versions exist for almost any language you can think of. But as with all new shiny tools in the development world, is it the right tool for you?
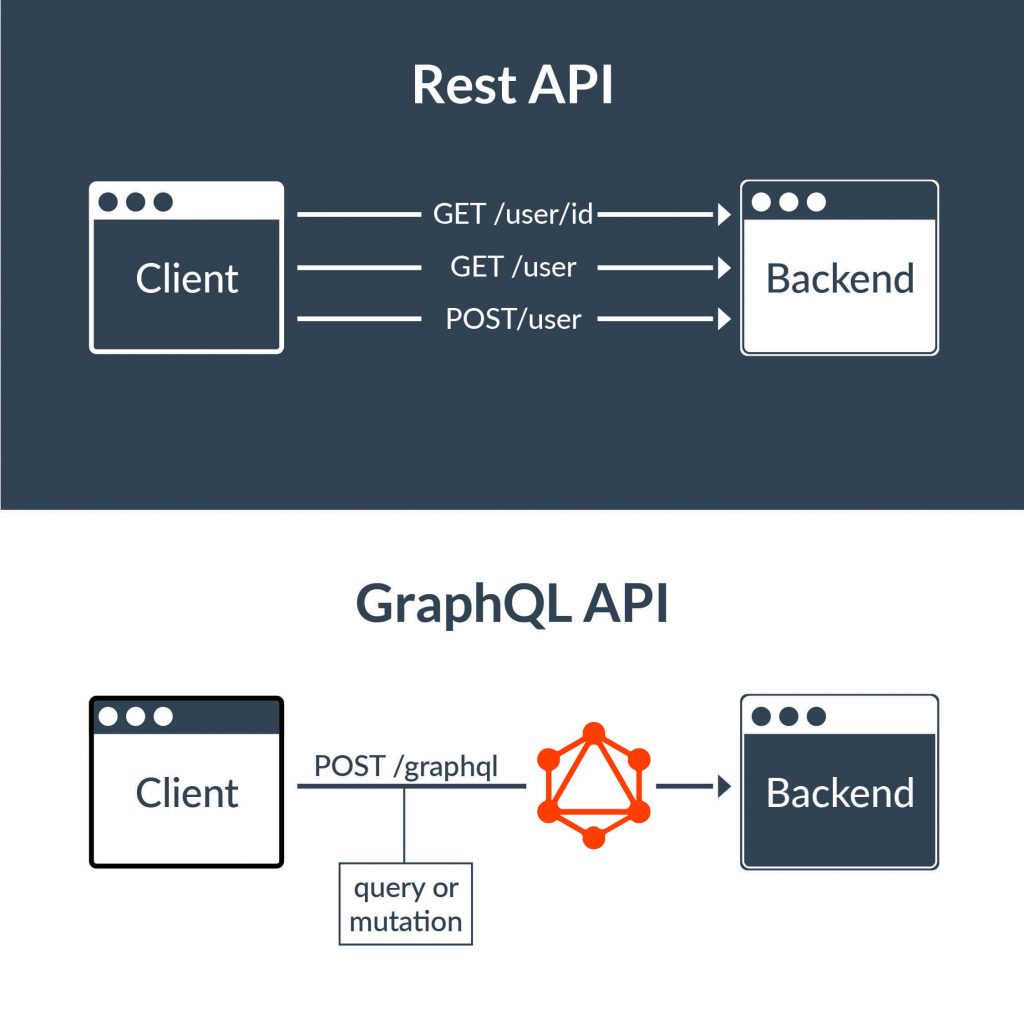
First, a quick introduction to GraphQL. Simply put, it’s another way of making HTTP requests to an API. It’s built on top of a standard REST system, with a key difference; there is only one endpoint that you make POST requests to. Most often the endpoint is found at “/graphql”. The body of the POST requests contains the query or mutation. The difference between a query and a mutation can be summed up as: queries fetch data, mutations change data.
The structure of the GraphQL queries is pretty simple. First we specify the query by its name. If we have arguments to pass (think query parameters in REST), we pass them as if the name of the query was a function. Next we declare the body of the query, which is mostly just declaring what fields we’d like to have returned in the response. Mutations behave almost identically. We can even have subqueries tied to fields on our initial query.
So what does GraphQL look like in practice? Let’s imagine we’re building a simple CRUD API to manage a blog. If we built it using REST, we’d probably want the following endpoints; a get all, a get by id, a create, an edit, a delete, and maybe a get comments by blog id. Now if we built it using GraphQL, that looks more like: a query to get blogs which can accept an argument of a blog id, and then mutations for create, edit, and delete. To get the comments, we’d define a subquery on our blog query. Using GraphQL we can build in the necessary logic to tie comments to their individual blog in field resolvers (resolvers are how we tell GraphQL to find data for a field). Then if the consumer wants the comments associated with a blog, all they have to do is add the comments field to their query.
To help understand the power of GraphQL, lets now imagine we’re building a UI to consume our new API. Well we’d probably want a front page to display all our blogs with limited info, we’d want the user to click the blog title and then see the rest of the blog, then perhaps we have a button to view the comments. With REST, we’d probably make a GET request to get the list of blogs, then a subsequent GET request to get the selected blog, and a final request to get the comments. With GraphQL, the UI has many more options. The UI could simply make one query and return all the available fields, or it could make one query for the only the fields needed for the list view and then a subsequent query for the individual blog with all its comments. The consumer decides how it wants to consume the API.
So now that we’ve established what GraphQL is and why it’s gained so much popularity, the next big question is: when does it make sense to use? From a consumer perspective, there's really no drawbacks to using that I’m aware of. However, it definitely makes things more complicated for the API in many cases. Now the difficulty in implementing mostly comes from the tools and language used to right the code, and the mindset shift from developing REST and SOAP API’s. There’s an initial learning curve for a development team when they first begin working on an API using GraphQL.
GraphQL is at it’s best when building API’s that may have many different consumers. It allows how data is consumed, to be controlled by the consumer. It allows the end users to easily see what data and actions they can perform (much like a tool like swagger does), and to structure data in a manner that works better for them; which is extremely powerful when you may not know how they plan to use your API. The other cases where GraphQL really shines is in one-to-many data relationships. In our blog example, we have a one-to-many relationship with the blog-to-comments. This is a great feature for reducing the complexity of tying data together. It’s easier to ask GraphQL to bring back a blog with all its relevant comments than it is to get the blog’s id and make another request to get the comments.
So when doesn’t it make sense to use GraphQL? Well the quick answer is: when it just adds bloat. By adding GraphQL to a project, we effectively add a very large piece of middleware. Most of the out-of-box implementations are very black-box (the code is usually open-source however). Which can lead to confusion for developers trying to transition from a more straightforward REST system. If we’re looking to build an API to pair with a UI and have and we don’t have many well defined one-to-many data relationships; then it’s likely a REST API will be just as effective and faster to implement.
The decision to use or not to use GraphQL is really a case-by-case question. There are many websites that use it and use it well. It likely won’t be a choice that ruins a project, but it is one that can play a major role in the architectural design. GraphQL is a well-defined query language that can help increase the usability of an API, but at the cost of increased complexity. It’s up to you to decide if your API needs more simplicity or usability.